Your template looks ok, but there is one more thing to consider which is the IAM role (IAMRoles array) that is needed the CF documentation lists this as an additional parameter.
myCluster:
Type: "AWS::Redshift::Cluster"
Properties:
DBName: "mydb"
MasterUsername: "master"
MasterUserPassword:
Ref: "MasterUserPassword"
NodeType: "dw.hs1.xlarge"
ClusterType: "single-node"
IamRoles:
- "arn:aws:iam::123456789012:role/S3Access"
Tags:
- Key: foo
Value: bar
The IAM role is needed to talk to the Glue / Athena catalog and authenticate your requests against your data in S3.
Answer from grundprinzip on Stack Overflowamazon redshift - Template to create IAM role for spectrum S3 access - Stack Overflow
Can I use cloud formation somehow to run a redshift command (to create an external spectrum table)?
You can write custom resources. I did it for simple queries to create IAM users for Aurora users and add “service” users to an Aurora table.
More on reddit.comamazon web services - When to use Redshift Spectrum for your Redshift data warehouse - Stack Overflow
Should I use spectrum or redshift native?
Videos
Your template looks ok, but there is one more thing to consider which is the IAM role (IAMRoles array) that is needed the CF documentation lists this as an additional parameter.
myCluster:
Type: "AWS::Redshift::Cluster"
Properties:
DBName: "mydb"
MasterUsername: "master"
MasterUserPassword:
Ref: "MasterUserPassword"
NodeType: "dw.hs1.xlarge"
ClusterType: "single-node"
IamRoles:
- "arn:aws:iam::123456789012:role/S3Access"
Tags:
- Key: foo
Value: bar
The IAM role is needed to talk to the Glue / Athena catalog and authenticate your requests against your data in S3.
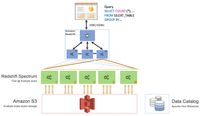
Amazon Redshift Spectrum is a feature of Amazon Redshift.
Simply launch a normal Amazon Redshift cluster and the features of Amazon Redshift Spectrum are available to you.
From Getting Started with Amazon Redshift Spectrum:
To use Redshift Spectrum, you need an Amazon Redshift cluster and a SQL client that's connected to your cluster so that you can execute SQL commands.
Would it be a best practice to use cloud formation to create the redshift cluster, but then to run commands manually in redshift to build out external tables, or should that external table creation command be run via cloud formation somehow? Thanks!!
This is a broad topic but I'll give a few thoughts.
First off Spectrum is a (often large) set of compute elements embedded in S3 that can do some aspect of the query plan. These part centered around applying WHERE conditions and performing aggregation (GROUP BY). There are also aspects of the query plan that cannot be perform in the S3 layer such as JOINs and advanced functions such as window functions.
The next thing to understand is that while these embedded compute elements are close to S3 in terms of access speed, the S3 service is far away from the Redshift cluster (network distance). If the large amount of data stored in S3 can be pared down to a small set that is shipped to Redshift then Spectrum can be a huge performance improvement. However, if the large amount of data stored in S3 needs to be moved to the Redshift cluster completely to perform the query then there can be a large hit to performance.
Spectrum can be a huge benefit; allowing for a very large amount of data to be filtered down quickly by a fleet of small compute elements. This can result in a big win in performance and in the amount of data that can be addressed.
With these in mind you will want to have data in Spectrum that your query plan will want to get a subset transferred from S3 to redshift. This in general will apply to your fact tables and not to your dim tables. However, if your queries aren't going to apply a WHERE clause to the fact table or aggregate the data down then you won't see the advantages. Also for this to work the WHERE clause needs to apply to a column in the fact table as JOINs cannot be done in S3 so filtering on dim columns won't help. Similarly and GROUP BY needs to be applied only on the fact table columns or this won't reduce the data coming to Redshift from S3.
So fact tables.
Data generally gets into Redshift through S3 and this can be done with the COPY command. You can also get data into Redshift from S3 using Spectrum. This can be a useful tool if other tools are also using S3 for this shared data. S3 can seem like a common data store for separate data systems. This can be useful for some data solutions.
You also bring up very large, infrequently used data. Like older historical data that is usually needed but is sometimes needed. This can be helpful in that older data can be offloaded from the Redshift cluster and the access time for this data isn't important as it is very infrequently used. There is a potential issue - The Redshift cluster can only work on a certain size of data given it's disk space and memory. So you can clog up your cluster if the amount of historical data is too large. This may mean that looking at the full set of historical data in one query may not be possible. Again if the data is aggregated or filtered in S3 this issue isn't a problem.
Bottom line - Spectrum is a great tool but isn't the right tool for every problem.
In general, put everything into 'normal' Amazon Redshift.
Redshift Spectrum is handy for accessing data stored in Amazon S3 without having to load it into the Redshift cluster, but it will not be as fast as accessing data stored in 'normal' Redshift.
Therefore, it is useful for rarely-accessed data or for one-off queries on a dataset without having to import the data into Redshift.
Do not use Spectrum as part of your normal ETL flow. One exception to this might be if you are receiving 'landing' data via Amazon S3 (eg Seed Files) -- rather than importing the tables into Redshift, they could be referenced via Spectrum. However, normal loading tools such as Fivetran can load the data directly into Redshift, which is preferable to using Spectrum.
Planning on using the redshift API to allow access into a table with roughly 5B rows. Currently that data is in S3 so to use the API, I am going to have to move that data to redshift. Should I use spectrum, or should I load the data natively? Which one do you think is cheaper long term if this API is hit multiple times a day? Thanks!