You've got a few problems there.
First, matches are case-sensitive unless you use the IGNORECASE/I flag to ignore case. So, 'AND' doesn't match 'and'.
Also, unless you use the VERBOSE/X flag, those spaces are part of the pattern. So, you're checking for 'AND ', not 'AND'. If you wanted that, you probably wanted spaces on each side, not just those sides (otherwise, 'band leader' is going to match…), and really, you probably wanted \b, not a space (otherwise a sentence starting with 'And another thing' isn't going to match).
Finally, if you think you need .* before and after your pattern and $ and ^ around it, there's a good chance you wanted to use search, findall, or finditer, rather than match.
So:
>>> s = "These are oranges and apples and pears, but not pinapples or .."
>>> r = re.compile(r'\bAND\b | \bOR\b | \bNOT\b', flags=re.I | re.X)
>>> r.findall(s)
['and', 'and', 'not', 'or']
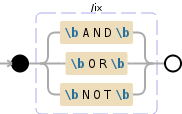
Debuggex Demo
Answer from abarnert on Stack OverflowYou've got a few problems there.
First, matches are case-sensitive unless you use the IGNORECASE/I flag to ignore case. So, 'AND' doesn't match 'and'.
Also, unless you use the VERBOSE/X flag, those spaces are part of the pattern. So, you're checking for 'AND ', not 'AND'. If you wanted that, you probably wanted spaces on each side, not just those sides (otherwise, 'band leader' is going to match…), and really, you probably wanted \b, not a space (otherwise a sentence starting with 'And another thing' isn't going to match).
Finally, if you think you need .* before and after your pattern and $ and ^ around it, there's a good chance you wanted to use search, findall, or finditer, rather than match.
So:
>>> s = "These are oranges and apples and pears, but not pinapples or .."
>>> r = re.compile(r'\bAND\b | \bOR\b | \bNOT\b', flags=re.I | re.X)
>>> r.findall(s)
['and', 'and', 'not', 'or']
Debuggex Demo
Try this:
>>> re.findall(r"\band\b|\bor\b|\bnot\b", "These are oranges and apples and pears, but not pinapples or ..")
['and', 'and', 'not', 'or']
a|b means match either a or b
\b represents a word boundary
re.findall(pattern, string) returns an array of all instances of pattern in string
Multiple words in any order using regex - Stack Overflow
python 3.x - Match multiple words in any order via one regex - Stack Overflow
python - Match a list of possible words in a string in any order - Stack Overflow
python - Match regex in any order - Stack Overflow
Videos
You can use
(?=.*test)(?=.*long)
Source: MySQL SELECT LIKE or REGEXP to match multiple words in one record
Use a capturing group if you want to extract the matches: (test)|(long)
Then depending on the language in use you can refer to the matched group using  2, for example.
2, for example.
You may leverage a non-capturing alternation group to match either VERSION or FREQ (optionally preceded with a word boundary, just check if it meets your requirements):
\b(?:VERSION|FREQ)="(.*?)"
See the regex demo
Details
\b- a leading word boundary(?:VERSION|FREQ)- eitherVERSIONorFREQ="- a="substring(.*?)- Group 1 (the actual output offindall): any 0+ chars other than line break chars, as few as possible"- a double quote.
See the Python demo:
import re
line='VERSION="OTHER" POWER="LOW" FREQ="OFF" MAXTUN="BLER"'
print(re.findall(r'\b(?:VERSION|FREQ)="(.*?)"', line))
# => ['OTHER', 'OFF']
A better idea, perhaps, is to capture key-value pairs and map them to a dictionary:
import re
line = 'VERSION="OTHER" POWER="LOW" FREQ="OFF" MAXTUN="BLER"'
results = re.findall(r'(VERSION|FREQ)="(.*?)"', line)
print(dict(results))
# => {'FREQ': 'OFF', 'VERSION': 'OTHER'}
See the Python demo.
I'm afraid there is no way to match in the order you want using regex: you could execute the part before | first, and then the part after |. Or order the result afterwards.
You could have tried looking for password validating regex, the site has a lot of them ;)
That said, you can use positive lookaheads to do that:
re.search(r"(?=.*[a-z])(?=.*[A-Z])(?=.*\d)", "1Az")
And to actually match the string...
re.search(r"(?=.*[a-z])(?=.*[A-Z])(?=.*\d).{3}", "1Az")
And now, to ensure that the password is 3 chars long:
re.search(r"^(?=.*[a-z])(?=.*[A-Z])(?=.*\d).{3}$", "1Az")
A positive lookahead (?= ... ) makes sure the expression inside is present in the string to be tested. So, the string has to have a lowercase character ((?=.*[a-z])), an uppercase character ((?=.*[A-Z])) and a digit ((?=.*\d)) for the regex to 'pass'.
Why not just:
if (re.search(r"[a-z]", input) and re.search(r"[A-Z]", input) and re.search(r"[0-9]", input)):
# pass
else
# don't pass
I'm very new to RegEx, but I'm trying to learn.
I'm looking to match two words which can be present anywhere in a body of text, separated by multiple line breaks/characters.
For example, let's say I want to match the word "apple" and "dog". It should match only if both words are present somewhere in the text. It can also be in any order.
It could be in something like:
Testing
Testing 2
Dog
Testing 3
Apple
I've tried things like: (apple)(dog) (apple)((.|\n)*)dog
(apple)((.|\n)*)dog works, but doesn't support the "any order"
What am I missing?