before running the above code you can manually set the env variable like this
import os
import sys
os.environ['PYSPARK_PYTHON'] = sys.executable
os.environ['PYSPARK_DRIVER_PYTHON'] = sys.executable
this worked in jupyter notebook for me.
Answer from amaresh hiremani on Stack OverflowHi All, i just installed Pyspark in my laptop and im facing this error while trying to run the below code, These are my envionment variables:
HADOOP_HOME = C:\Programs\hadoop
JAVA_HOME = C:\Programs\Java
PYSPARK_DRIVER_PYTHON = C:\Users\Asus\AppData\Local\Programs\Python\Python313\python.exe
PYSPARK_HOME = C:\Users\Asus\AppData\Local\Programs\Python\Python313\python.exe
PYSPARK_PYTHON = C:\Users\Asus\AppData\Local\Programs\Python\Python313\python.exe
SPARK_HOME = C:\Programs\Spark
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local").appName("PySpark Installation Test").getOrCreate()
df = spark.createDataFrame([(1, "Hello"), (2, "World")], ["id", "message"])
df.show()Error logs:
Py4JJavaError Traceback (most recent call last)
Cell In[1], line 5
3 spark = SparkSession.builder.master("local").appName("PySpark Installation Test").getOrCreate()
4 df = spark.createDataFrame([(1, "Hello"), (2, "World")], ["id", "message"])
----> 5 df.show()
File , in DataFrame.show(self, n, truncate, vertical)
887 def show(self, n: int = 20, truncate: Union[bool, int] = True, vertical: bool = False) -> None:
888 """Prints the first ``n`` rows to the console.
889
890 .. versionadded:: 1.3.0
(...)
945 name | Bob
946 """
--> 947 print(self._show_string(n, truncate, vertical))
File , in DataFrame._show_string(self, n, truncate, vertical)
959 raise PySparkTypeError(
960 error_class="NOT_BOOL",
961 message_parameters={"arg_name": "vertical", "arg_type": type(vertical).__name__},
962 )
964 if isinstance(truncate, bool) and truncate:
--> 965 return self._jdf.showString(n, 20, vertical)
966 else:
967 try:
File , in JavaMember.__call__(self, *args)
1316 command = proto.CALL_COMMAND_NAME +\
1317 self.command_header +\
1318 args_command +\
1319 proto.END_COMMAND_PART
1321 answer = self.gateway_client.send_command(command)
-> 1322 return_value = get_return_value(
1323 answer, self.gateway_client, self.target_id, self.name)
1325 for temp_arg in temp_args:
1326 if hasattr(temp_arg, "_detach"):
File , in capture_sql_exception.<locals>.deco(*a, **kw)
177 def deco(*a: Any, **kw: Any) -> Any:
178 try:
--> 179 return f(*a, **kw)
180 except Py4JJavaError as e:
181 converted = convert_exception(e.java_exception)
File , in get_return_value(answer, gateway_client, target_id, name)
324 value = OUTPUT_CONVERTER[type](answer[2:], gateway_client)
325 if answer[1] == REFERENCE_TYPE:
--> 326 raise Py4JJavaError(
327 "An error occurred while calling {0}{1}{2}".
328 format(target_id, ".", name), value)
329 else:
330 raise Py4JError(
331 "An error occurred while calling {0}{1}{2}. Trac{3}\n".
332 format(target_id, ".", name, value))
Py4JJavaError: An error occurred while calling o43.showString.
: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 1 times, most recent failure: Lost task 0.0 in stage 0.0 (TID 0) (Bat-Computer executor driver): org.apache.spark.SparkException: Python worker exited unexpectedly (crashed)
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator$$anonfun$1.applyOrElse(PythonRunner.scala:612)
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator$$anonfun$1.applyOrElse(PythonRunner.scala:594)
at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:38)
at org.apache.spark.api.python.PythonRunner$$anon$3.read(PythonRunner.scala:789)
at org.apache.spark.api.python.PythonRunner$$anon$3.read(PythonRunner.scala:766)
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.hasNext(PythonRunner.scala:525)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:491)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenEvaluatorFactory$WholeStageCodegenPartitionEvaluator$$anon$1.hasNext(WholeStageCodegenEvaluatorFactory.scala:43)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$getByteArrayRdd$1(SparkPlan.scala:388)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2(RDD.scala:893)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2$adapted(RDD.scala:893)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:367)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:331)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:93)
at org.apache.spark.TaskContext.runTaskWithListeners(TaskContext.scala:166)
at org.apache.spark.scheduler.Task.run(Task.scala:141)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$4(Executor.scala:620)
at org.apache.spark.util.SparkErrorUtils.tryWithSafeFinally(SparkErrorUtils.scala:64)
at org.apache.spark.util.SparkErrorUtils.tryWithSafeFinally$(SparkErrorUtils.scala:61)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:94)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:623)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1144)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:642)
at java.base/java.lang.Thread.run(Thread.java:1583)
Caused by: java.io.EOFException
at java.base/java.io.DataInputStream.readFully(DataInputStream.java:210)
at java.base/java.io.DataInputStream.readInt(DataInputStream.java:385)
at org.apache.spark.api.python.PythonRunner$$anon$3.read(PythonRunner.scala:774)
... 26 more
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.failJobAndIndependentStages(DAGScheduler.scala:2856)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:2792)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:2791)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2791)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1(DAGScheduler.scala:1247)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1$adapted(DAGScheduler.scala:1247)
at scala.Option.foreach(Option.scala:407)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:1247)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:3060)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2994)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2983)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:989)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2393)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2414)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2433)
at org.apache.spark.sql.execution.SparkPlan.executeTake(SparkPlan.scala:530)
at org.apache.spark.sql.execution.SparkPlan.executeTake(SparkPlan.scala:483)
at org.apache.spark.sql.execution.CollectLimitExec.executeCollect(limit.scala:61)
at org.apache.spark.sql.Dataset.collectFromPlan(Dataset.scala:4333)
at org.apache.spark.sql.Dataset.$anonfun$head$1(Dataset.scala:3316)
at org.apache.spark.sql.Dataset.$anonfun$withAction$2(Dataset.scala:4323)
at org.apache.spark.sql.execution.QueryExecution$.withInternalError(QueryExecution.scala:546)
at org.apache.spark.sql.Dataset.$anonfun$withAction$1(Dataset.scala:4321)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$6(SQLExecution.scala:125)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:201)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:108)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:900)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:66)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:4321)
at org.apache.spark.sql.Dataset.head(Dataset.scala:3316)
at org.apache.spark.sql.Dataset.take(Dataset.scala:3539)
at org.apache.spark.sql.Dataset.getRows(Dataset.scala:280)
at org.apache.spark.sql.Dataset.showString(Dataset.scala:315)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:75)
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:52)
at java.base/java.lang.reflect.Method.invoke(Method.java:580)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:374)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182)
at py4j.ClientServerConnection.run(ClientServerConnection.java:106)
at java.base/java.lang.Thread.run(Thread.java:1583)
Caused by: org.apache.spark.SparkException: Python worker exited unexpectedly (crashed)
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator$$anonfun$1.applyOrElse(PythonRunner.scala:612)
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator$$anonfun$1.applyOrElse(PythonRunner.scala:594)
at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:38)
at org.apache.spark.api.python.PythonRunner$$anon$3.read(PythonRunner.scala:789)
at org.apache.spark.api.python.PythonRunner$$anon$3.read(PythonRunner.scala:766)
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.hasNext(PythonRunner.scala:525)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:491)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenEvaluatorFactory$WholeStageCodegenPartitionEvaluator$$anon$1.hasNext(WholeStageCodegenEvaluatorFactory.scala:43)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$getByteArrayRdd$1(SparkPlan.scala:388)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2(RDD.scala:893)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2$adapted(RDD.scala:893)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:367)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:331)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:93)
at org.apache.spark.TaskContext.runTaskWithListeners(TaskContext.scala:166)
at org.apache.spark.scheduler.Task.run(Task.scala:141)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$4(Executor.scala:620)
at org.apache.spark.util.SparkErrorUtils.tryWithSafeFinally(SparkErrorUtils.scala:64)
at org.apache.spark.util.SparkErrorUtils.tryWithSafeFinally$(SparkErrorUtils.scala:61)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:94)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:623)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1144)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:642)
... 1 more
Caused by: java.io.EOFException
at java.base/java.io.DataInputStream.readFully(DataInputStream.java:210)
at java.base/java.io.DataInputStream.readInt(DataInputStream.java:385)
at org.apache.spark.api.python.PythonRunner$$anon$3.read(PythonRunner.scala:774)
... 26 more~\Workspace\Projects\Python\PySpark\MyFirstPySpark_Proj\spark_venv\Lib\site-packages\pyspark\sql\dataframe.py:947~\Workspace\Projects\Python\PySpark\MyFirstPySpark_Proj\spark_venv\Lib\site-packages\pyspark\sql\dataframe.py:965~\Workspace\Projects\Python\PySpark\MyFirstPySpark_Proj\spark_venv\Lib\site-packages\py4j\java_gateway.py:1322~\Workspace\Projects\Python\PySpark\MyFirstPySpark_Proj\spark_venv\Lib\site-packages\pyspark\errors\exceptions\captured.py:179~\Workspace\Projects\Python\PySpark\MyFirstPySpark_Proj\spark_venv\Lib\site-packages\py4j\protocol.py:326.\ne:\nVideos
before running the above code you can manually set the env variable like this
import os
import sys
os.environ['PYSPARK_PYTHON'] = sys.executable
os.environ['PYSPARK_DRIVER_PYTHON'] = sys.executable
this worked in jupyter notebook for me.
The key is in this part of the error message:
RuntimeError: Python in worker has different version 3.9 than that in driver 3.10, PySpark cannot run with different minor versions. Please check environment variables PYSPARK_PYTHON and PYSPARK_DRIVER_PYTHON are correctly set.
You need to have exactly the same Python versions in driver and worker nodes.
Probably a quick solution would be to downgrade your Python version to 3.9 (assuming driver is running on the client you're using).
Hey everyone!
I recently started working with Apache Spark, and its PySpark implementation in a professional environment, thus I am by no means an expert, and I am facing an error with Py4J.
In more details, I have installed Apache Spark, and already set up the SPARK_HOME, HADOOP_HOME, JAVA_HOME environment variables. As I want to run PySpark without using pip install pyspark, I have set up a PYTHONPATH environment variable, with values pointing to the python folder of Apache Spark and inside the py4j.zip.
My issue is that when I create a dataframe from scratch and use the command df.show() I get the Error
*"*Py4JJavaError: An error occurred while calling o143.showString. : org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 4.0 failed 1 times, most recent failure: Lost task 0.0 in stage 4.0 (TID 4) (xxx-yyyy.mshome.net executor driver): org.apache.spark.SparkException: Python worker failed to connect back".
However, the command works as it should when the dataframe is created, for example, by reading a csv file. Other commands that I have also tried, works as they should.
The version of the programs that I use are:
Python 3.11.9 (always using venv, so Python is not in path)
Java 11
Apache Spark 3.5.1 (and Hadoop 3.3.6 for the win.utls file and hadoop.dll)
Visual Studio Code
Windows 11
I have tried other version of Python (3.11.8, 3.12.4) and Apache Spark (3.5.2), with the same response
Any help would be greatly appreciated!
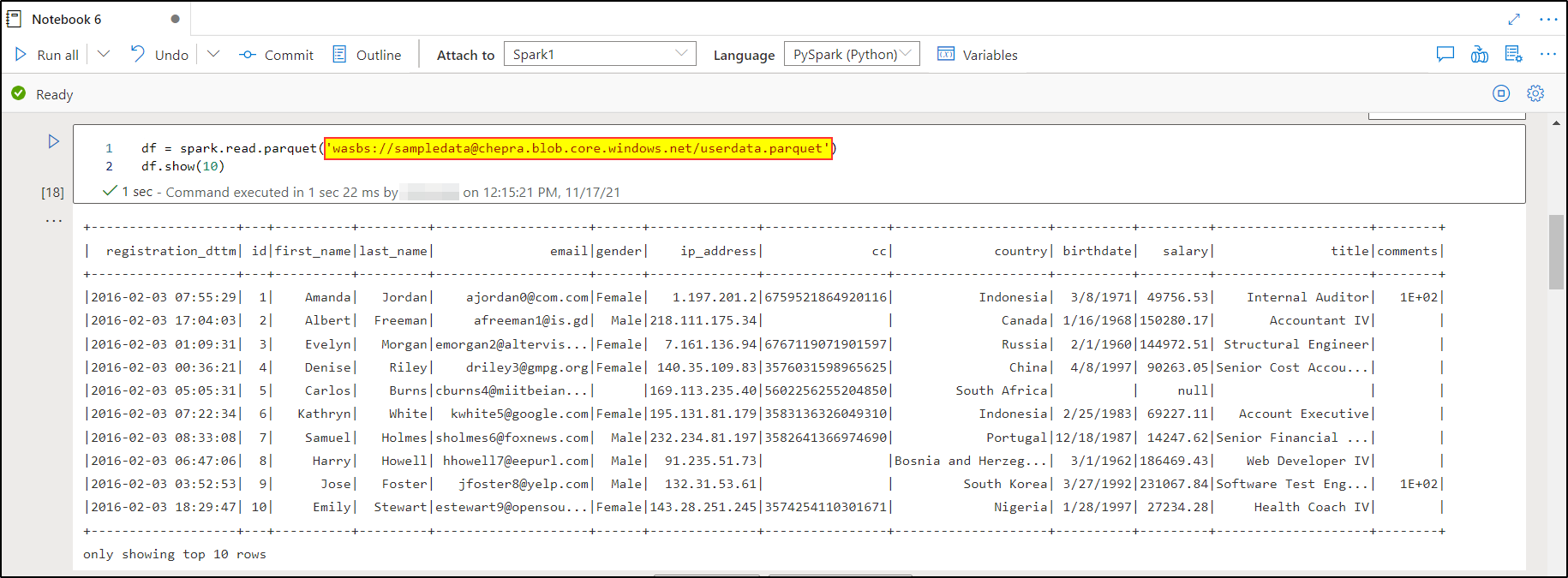
The following two pictures just show an example of the issue that I am facing.
----------- UPDATED SOLUTION -----------
In the end, also thanks to the suggestions in the comments, I figured out a way to make PySpark work with the following implementation. After running this code in a cell, PySpark is recognized as it should and the code runs without issues even for the manually created dataframe, Hopefully, it can also be helpful to others!
# Import the necessary libraries
import os, sys
# Add the necessary environment variables
os.environ["PYSPARK_PYTHON"] = sys.executable
os.environ["spark_python"] = os.getenv('SPARK_HOME') + "\\python"
os.environ["py4j"] = os.getenv('SPARK_HOME') + "\\python\lib\py4j-0.10.9.7-src.zip"
# Retrieve the values from the environment variables
spark_python_path = os.environ["spark_python"]
py4j_zip_path = os.environ["py4j"]
# Add the paths to sys.path
for path in [spark_python_path, py4j_zip_path]:
if path not in sys.path:
sys.path.append(path)
# Verify that the paths have been added to sys.path
print("sys.path:", sys.path)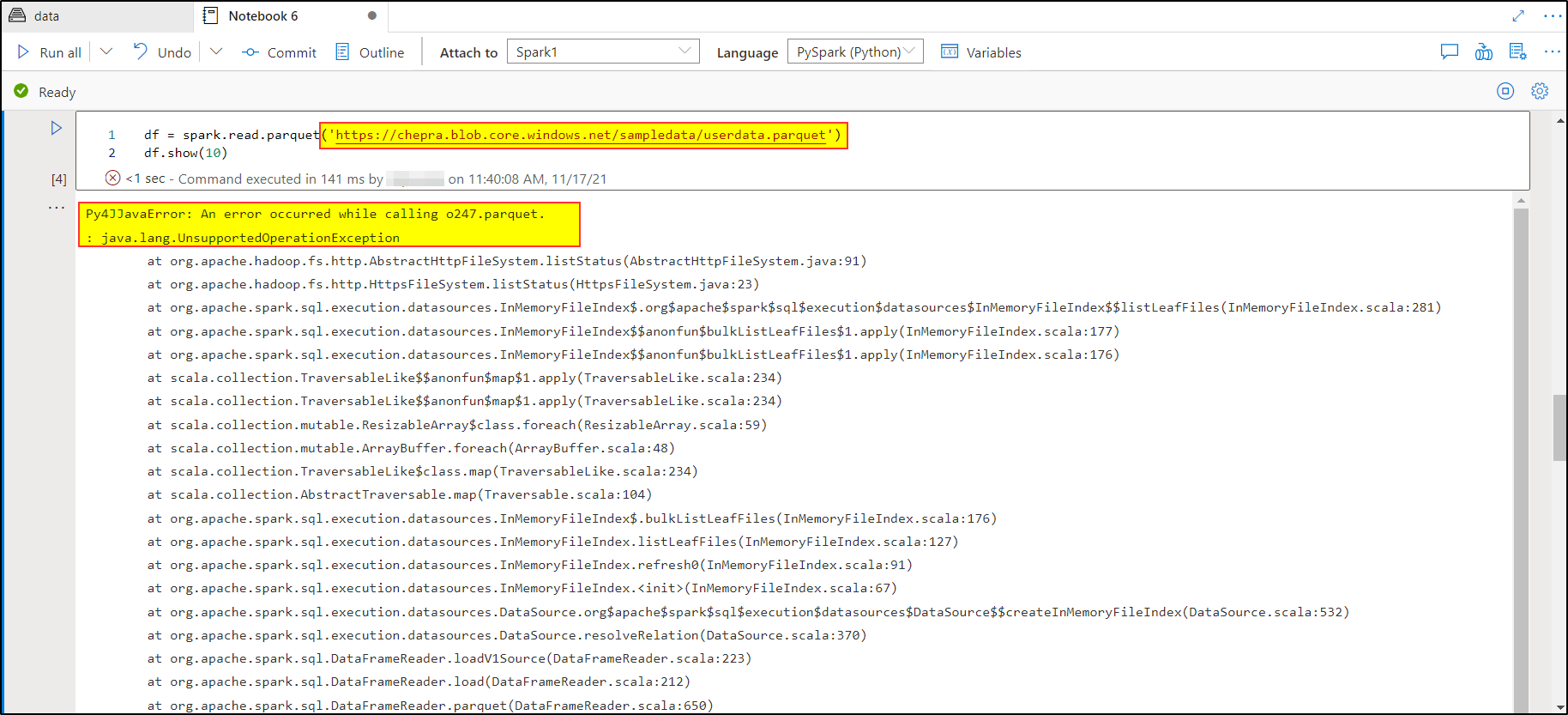

 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how Yeah I had the same problem long time ago in Pyspark in Anaconda I tried several ways to rectify this finally I found on my own by installing Java for anaconda separately afterwards there is no Py4jerror.
conda install -c cyclus java-jdk
https://anaconda.org/cyclus/java-jdk
Pyspark 2.1.0 is not compatible with python 3.6, see https://issues.apache.org/jira/browse/SPARK-19019.
You need to use earlier python version or you can try building master or 2.1 branch from github and it should work.