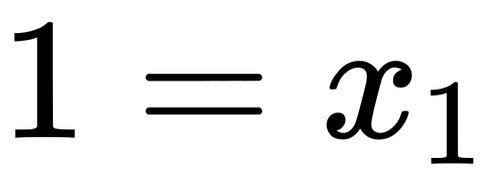
a = np.array([0.123456789121212,2,3], dtype=np.float16)
print("16bit: ", a[0])
a = np.array([0.123456789121212,2,3], dtype=np.float32)
print("32bit: ", a[0])
b = np.array([0.123456789121212121212,2,3], dtype=np.float64)
print("64bit: ", b[0])
- 16bit: 0.1235
- 32bit: 0.12345679
- 64bit: 0.12345678912121212
float32 is a 32 bit number - float64 uses 64 bits.
That means that float64’s take up twice as much memory - and doing operations on them may be a lot slower in some machine architectures.
However, float64’s can represent numbers much more accurately than 32 bit floats.
They also allow much larger numbers to be stored.
For your Python-Numpy project I'm sure you know the input variables and their nature.
To make a decision we as programmers need to ask ourselves
- What kind of precision does my output need?
- Is speed not an issue at all?
- what precision is needed in parts per million?
A naive example would be if I store weather data of my city as [12.3, 14.5, 11.1, 9.9, 12.2, 8.2]
Next day Predicted Output could be of 11.5 or 11.5164374
do your think storing float 32 or float 64 would be necessary?
Difference between Python float and numpy float32 - Stack Overflow
If float32 is only 6-7 digits, how do values where the first 6-7 digits are just 0s make sense?
python - I want to know what does np.float32 means - Stack Overflow
Consequence of using single (float32) or double (float64) precision for saving interpolated data
Python's standard float type is a C double: http://docs.python.org/2/library/stdtypes.html#typesnumeric
NumPy's standard numpy.float is the same, and is also the same as numpy.float64.
Data type-wise numpy floats and built-in Python floats are the same, however boolean operations on numpy floats return np.bool_ objects, which always return False for val is True. Example below:
In [1]: import numpy as np
...: an_np_float = np.float32(0.3)
...: a_normal_float = 0.3
...: print(a_normal_float, an_np_float)
...: print(type(a_normal_float), type(an_np_float))
0.3 0.3
<class 'float'> <class 'numpy.float32'>
Numpy floats can arise from scalar output of array operations. If you weren't checking the data type, it is easy to confuse numpy floats for native floats.
In [2]: criterion_fn = lambda x: x <= 0.5
...: criterion_fn(a_normal_float), criterion_fn(an_np_float)
Out[2]: (True, True)
Even boolean operations look correct. However the result of the numpy float isn't a native boolean datatype, and thus can't be truthy.
In [3]: criterion_fn(a_normal_float) is True, criterion_fn(an_np_float) is True
Out[3]: (True, False)
In [4]: type(criterion_fn(a_normal_float)), type(criterion_fn(an_np_float))
Out[4]: (bool, numpy.bool_)
According to this github thread, criterion_fn(an_np_float) == True will evaluate properly, but that goes against the PEP8 style guide.
Instead, extract the native float from the result of numpy operations. You can do an_np_float.item() to do it explicitly (ref: this SO post) or simply pass values through float().
I was messing around with float32 numbers and got values like 1.4e-44. I'm not good at scientific notation, but I printed variables out with 100 digits being shown instead of scientific notation, and it goes something like .000000000000000000000000125321 (not exact, just an example)
But how does that make sense if float32 only allows 6-7 digits? Wouldn't that mean only the 0s are valid?
It's generating a 2D list of float32 (a float type with 32 bits).
The formatting is a bit hard to understand at first but, basically, it's creating one list with [], and inside that list it's creating new lists ([], []) with two variables. So, each item in the first list is a second list, with two items in the second list:
points_B = [ [item1, item2], [item3, item4] ]
To access the second item, we could write:
x = points_B[0][1]
The float32 datatypes in the list are referring to points which are then being passed into getPerspectiveTransform which is being used to compute the transformation matrix, which, to my understanding, just defines the area of the image that you want to warp.
np.float32(a) is equivalent to np.array(a, dtype=np.float32). it's a data type of some size.
a = [1, 2, 3] # a(list,len=3): [1, 2, 3]
b = np.float32(a) # b(numpy.ndarray,s=(3,),dtype=float32): [1.00, 2.00, 3.00]
c = np.array(a, dtype=np.float32) # c(numpy.ndarray,s=(3,),dtype=float32): [1.00, 2.00, 3.00]
a = [100, 200, 300] # a = [100, 200, 300]
b = np.uint8(a) # b(numpy.ndarray,s=(3,),dtype=uint8): [100, 200, 44]
c = np.array(a, dtype=np.uint8) # c = np.array(a, dtype=np.uint8)
d = np.int32(a) # d(numpy.ndarray,s=(3,),dtype=int32): [100, 200, 300]
Notice on the second example that an unsigned int8 is not big enough for the number 300 - hence overflow (max val for uint8 is 255).