machine learning - Where is it best to use svm with linear kernel? - Stack Overflow
svm - What are kernels in support vector machine? - Cross Validated
machine learning - How to select kernel for SVM? - Cross Validated
NEED HELP WITH SVM KERNEL CODE IN PYTHON FROM SCRATCH
Videos
One more thing to add: linear SVM is less prone to overfitting than non-linear. And you need to decide which kernel to choose based on your situation: if your number of features is really large compared to the training sample, just use linear kernel; if your number of features is small, but the training sample is large, you may also need linear kernel but try to add more features; if your feature number is small (10^0 - 10^3), and the sample number is intermediate (10^1 - 10^4), use Gaussian kernel will be better.
As far as I know, SVM with linear kernel is usually comparable with logistic regression .
Linear kernel has some advantages but probably (in my opinion) the most significant one is the fact that generally is way faster to train in comparison with non-linear kernels such as RBF.
If your dataset size is in terms of gigabytes, you would see that the training time difference is huge (minutes vs. hours).
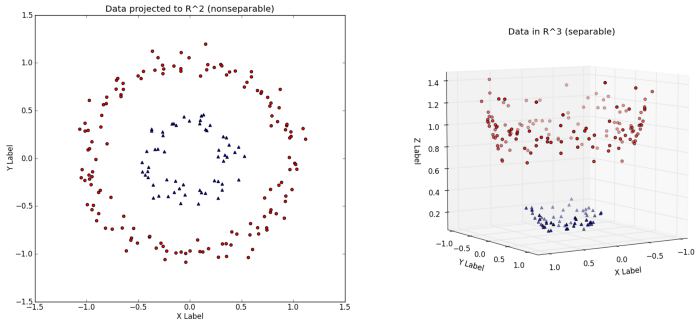
In principle, a Kernel is just a feature transformation in an (infinite) feature space. It is often the case, that your feature space is to simple/small, so that you are not able to divide the data properly (in a linear way). Just look at the pciture of this blog (https://towardsdatascience.com/understanding-the-kernel-trick-e0bc6112ef78): In an 2D Feature space, you have no chance to separte datapoints in a linear way. Therefore just use a transformation (gaussian-kernel, polynomial kernel, etc. ) to achieve a higher feature space. In the 3D space, the circle can be divided by a linear function.
In principal, those kernels are just a function, which is computed on every datapoint. The mathematical trick behind those kernels is, that you do not have to actually compute this transformation on each datapoint. But this goes to far i think.
We define kernels as real-valued functions $\kappa(x,x')\in\mathbb{R}$ where $x,x'\in\mathbb{R}^n$.
Typically,
- $\kappa(x,x')\geq 0$
- $\kappa(x,x')=\kappa(x',x)$
So a kernel can be interpreted as a measure of similarity. For example, $$\kappa(x,x')=x^Tx'$$
What we use in support vector machines are Mercer kernels. If a kernel is Mercer, then there exists a function $\phi:\mathbb{R}^n\rightarrow\mathbb{R}^m$ for some $m$ (which can also be infinite as in the case of the RBF kernel), such that:
$$\kappa(x,x')=\phi(x)^T\phi(x')$$
For example, let $\kappa(x,x') = (1+x^Tx')^2$ for $x,x'\in\mathbb{R}^2$.
$\Rightarrow\kappa(x,x') = (1+x_1x'_1+x_2x'_2)^2$
$\Rightarrow\kappa(x,x') = 1+2x_1x'_1+2x_2x'_2+(x_1x'_1)^2+(x_2x'_2)^2+2x_1x'_1x_2x'_2$
$\kappa(x,x')$ can be written as $\phi(x)^T\phi(x')$ where $\phi(x) = [1,\sqrt{2}x_1,\sqrt{2}x_2,x_1^2,x_2^2,\sqrt{2}x_1x_2]^T$.
So this kernel is equivalent to working in a 6-dimensional space.
Also, the complexity to get $(1+x^Tx')^2$ for $x,x'\in\mathbb{R}^2$ is lesser than the complexity to get $\phi(x)^T\phi(x')$ for $\phi(x),\phi(x')\in\mathbb{R}^6$.
The kernel is effectively a similarity measure, so choosing a kernel according to prior knowledge of invariances as suggested by Robin (+1) is a good idea.
In the absence of expert knowledge, the Radial Basis Function kernel makes a good default kernel (once you have established it is a problem requiring a non-linear model).
The choice of the kernel and kernel/regularisation parameters can be automated by optimising a cross-valdiation based model selection (or use the radius-margin or span bounds). The simplest thing to do is to minimise a continuous model selection criterion using the Nelder-Mead simplex method, which doesn't require gradient calculation and works well for sensible numbers of hyper-parameters. If you have more than a few hyper-parameters to tune, automated model selection is likely to result in severe over-fitting, due to the variance of the model selection criterion. It is possible to use gradient based optimization, but the performance gain is not usually worth the effort of coding it up).
Automated choice of kernels and kernel/regularization parameters is a tricky issue, as it is very easy to overfit the model selection criterion (typically cross-validation based), and you can end up with a worse model than you started with. Automated model selection also can bias performance evaluation, so make sure your performance evaluation evaluates the whole process of fitting the model (training and model selection), for details, see
G. C. Cawley and N. L. C. Talbot, Preventing over-fitting in model selection via Bayesian regularisation of the hyper-parameters, Journal of Machine Learning Research, volume 8, pages 841-861, April 2007. (pdf)
and
G. C. Cawley and N. L. C. Talbot, Over-fitting in model selection and subsequent selection bias in performance evaluation, Journal of Machine Learning Research, vol. 11, pp. 2079-2107, July 2010.(pdf)
If you are not sure what would be best you can use automatic techniques of selection (e.g. cross validation, ... ). In this case you can even use a combination of classifiers (if your problem is classification) obtained with different kernel.
However, the "advantage" of working with a kernel is that you change the usual "Euclidean" geometry so that it fits your own problem. Also, you should really try to understand what is the interest of a kernel for your problem, what is particular to the geometry of your problem. This can include:
- Invariance: if there is a familly of transformations that do not change your problem fundamentally, the kernel should reflect that. Invariance by rotation is contained in the gaussian kernel, but you can think of a lot of other things: translation, homothetie, any group representation, ....
- What is a good separator ? if you have an idea of what a good separator is (i.e. a good classification rule) in your classification problem, this should be included in the choice of kernel. Remmeber that SVM will give you classifiers of the form
$$ \hat{f}(x)=\sum_{i=1}^n \lambda_i K(x,x_i)$$
If you know that a linear separator would be a good one, then you can use Kernel that gives affine functions (i.e. $K(x,x_i)=\langle x,A x_i\rangle+c$). If you think smooth boundaries much in the spirit of smooth KNN would be better, then you can take a gaussian kernel...