Medium
medium.com › intuition › understanding-l1-and-l2-regularization-with-analytical-and-probabilistic-views-8386285210fc
Understanding L1 and L2 regularization with analytical and probabilistic views | by Yuki Shizuya | Intuition | Medium
June 6, 2024 - To obtain the parameter update equation, we need to decompose the XB term. We divide it into the i-th column of the XB and the other columns. As you can see, we can derive the parameter-update formula. How about the L1 regularization term? We will introduce soft-thresholding to solve it.
GeeksforGeeks
geeksforgeeks.org › machine learning › regularization-in-machine-learning
Regularization in Machine Learning - GeeksforGeeks
Lower MSE means better accuracy. The coefficients reflect the regularized feature weights. Elastic Net Regression is a combination of both L1 as well as L2 regularization. It combines both L1 (absolute values) and L2 (squared values) penalties on the coefficients.
Published April 30, 2026
Videos
L1 Regularization - The Lasso
04:04
L1 vs L2 Regularization - YouTube
07:44
L1 Regularization method | lasso regression | Machine Learning ...
21:14
Regulaziation in Machine Learning | L1 and L2 Regularization | ...
L1 regularized problems have no closed form solution, but ...
17:11
The Lasso problem: Using L1 regularization for feature selection ...
Built In
builtin.com › data-science › l2-regularization
L1 and L2 Regularization Methods, Explained | Built In
Although it’s used to resolve overfitting, L1 regularization can actually cause model underfitting based on the lambda value. If lambda is zero, then regularization is disabled. Here, we’ll get back ordinary least squares (OLS) whereas a very large value will make coefficients zero.
Medium
medium.com › @alejandro.itoaramendia › l1-and-l2-regularization-part-1-a-complete-guide-51cf45bb4ade
L1 Regularization (Part 1): A Complete Guide | Medium
March 31, 2024 - Feature selection: By penalising the absolute values of the coefficients, L1 regularization attempts to drive the coefficient values of less relevant features towards 0, thus, keeping only the relevant features.
Towards Data Science
towardsdatascience.com › home › latest › understanding l1 and l2 regularization
Understanding l1 and l2 Regularization | Towards Data Science
January 16, 2025 - Lasso (Least Absolute and Selection Operator) regression performs an L1 regularization, which adds a penalty equal to the absolute value of the magnitude of the coefficients, as we can see in the image above in the blue rectangle (lambda is the regularization parameter).
technique in mathematics, statistics, and computer science to make a model more generalizable and transferable
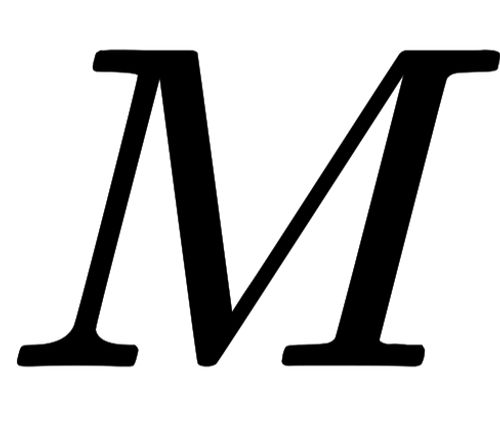
Wikipedia
en.wikipedia.org › wiki › Regularization_(mathematics)
Regularization (mathematics) - Wikipedia
2 weeks ago - {\displaystyle R} is the L1 regularizer, the proximal operator is equivalent to the soft-thresholding operator,
ML Glossary
ml-cheatsheet.readthedocs.io › en › latest › regularization.html
Regularization — ML Glossary documentation - Read the Docs
If w is negative, the regularization parameter \(\lambda\) < 0 will push w to be less negative, by adding \(\lambda\) to w. hence this has the effect of pushing w towards 0. ... def update_weights_with_l1_regularization(features, targets, weights, lr,lambda): ''' Features:(200, 3) Targets: (200, 1) Weights:(3, 1) ''' predictions = predict(features, weights) #Extract our features x1 = features[:,0] x2 = features[:,1] x3 = features[:,2] # Use matrix cross product (*) to simultaneously # calculate the derivative for each weight d_w1 = -x1*(targets - predictions) d_w2 = -x2*(targets - predictions)
Medium
blog.mlreview.com › l1-norm-regularization-and-sparsity-explained-for-dummies-5b0e4be3938a
L1 Norm Regularization and Sparsity Explained for Dummies | by Shi Yan | ML Review
January 6, 2018 - So if your initial goal is finding the best vector x to minimize a loss function f(x), your new task should incorporate the L1 norm of x into the formula, finding the minimum (f(x) + L1norm(x)).
Regenerativetoday
regenerativetoday.com › understanding-regularization-in-plain-language-l1-and-l2-regularization
Understanding Regularization in Plain Language: L1 and L2 Regularization – Regenerative
March 4, 2022 - It is known as Lasso regression ... parameter. As you can see the regularization term is the sum of the absolute values of all the slopes multiplied by the term lambda....
CCS NEU
ccs.neu.edu › home › vip › teach › MLcourse › 1.1_LinearRegression › LectureNotes › L1_and_L2_reg_regression,pdf.pdf pdf
Understanding L1 and L2 regularization with analytical and ...
https://medium.com/intuition/understanding-l1-and-l2-regularization-with-analytical-and-probabilistic-views-8386285210fc#c955 ... XB and the other columns. As you can see, we can derive the · parameter-update formula.
Google
developers.google.com › machine learning › overfitting: l2 regularization
Overfitting: L2 regularization | Machine Learning | Google for Developers
April 9, 2026 - This can be challenging. Worst of all, once you find that elusive balance, you may have to ultimately change the learning rate. And, when you change the learning rate, you'll again have to find the ideal regularization rate. Key terms: Early stopping · L1 regularization ·
Medium
medium.com › analytics-vidhya › regularization-understanding-l1-and-l2-regularization-for-deep-learning-a7b9e4a409bf
Regularization — Understanding L1 and L2 regularization for Deep Learning | by Ujwal Tewari | Analytics Vidhya | Medium
January 19, 2024 - L1 regularization is a method of doing regularization. It tends to be more specific than gradient descent, but it is still a gradient descent optimization problem. Formula and high level meaning over here: Formula for L1 regularization terms · Lasso Regression (Least Absolute Shrinkage and Selection Operator) adds “Absolute value of magnitude” of coefficient, as penalty term to the loss function.
APXML
apxml.com › courses › deep-learning-regularization-optimization › chapter-2-weight-regularization › l1-regularization-math
L1 Regularization Math
L1 regularization modifies the standard loss function by adding a penalty term proportional to the sum of the absolute values of all the weights in the network.
Analytics Steps
analyticssteps.com › blogs › l2-and-l1-regularization-machine-learning
L2 vs L1 Regularization in Machine Learning | Ridge and Lasso Regularization
L2 regularization disperse the error terms in all the weights that leads to more accurate customized final models. ... (press enter somehow posted the comment). Also how is L1 harder to differentiate than L2? L1's derivative is the logical operator of w>0 while L2 is 2*w. Are you suggesting that floating point operation is (much) faster than integer logic operation? ... I am not able to load formula images...
Weights & Biases
wandb.ai › mostafaibrahim17 › ml-articles › reports › Understanding-L1-and-L2-regularization-techniques-for-optimized-model-training--Vmlldzo3NzYwNTM5
Understanding L1 and L2 regularization: techniques for optimized model training | ml-articles – Weights & Biases
1 day ago - Unlike L1 regularization, which adds the absolute values of the coefficients to the loss function, L2 regularization adds the square of the coefficients. This difference in approach leads to different characteristics and effects on the model. The L2 regularization term is the sum of the squares of the coefficients, multiplied by a regularization parameter (λ). ... As you can see in the image above, the only difference in the mathematical formula between L1 and L2 is that the βi is squared and not absolute.
Dataheadhunters
dataheadhunters.com › academy › understanding-regularization-l1-vs-l2-methods-compared
Understanding Regularization: L1 vs. L2 Methods Compared
January 7, 2024 - The L1 regularization formula adds the absolute value of the model coefficients as a penalty term to the loss function:
Spot Intelligence
spotintelligence.com › home › l1 and l2 regularization explained, when to use them & practical how to examples
L1 And L2 Regularization Explained, When To Use Them & Practical How To Examples
November 21, 2024 - The most common regularization techniques used are L1 regularization (Lasso), L2 regularization (Ridge), and Elastic Net regularization. L1 regularization adds the sum of the absolute values of the model’s coefficients to the loss function, encouraging sparsity and feature selection.
Statistics How To
statisticshowto.com › home › regularization: simple definition, l1 & l2 penalties
Regularization: Simple Definition, L1 & L2 Penalties - Statistics How To
July 7, 2020 - Regularization works by biasing ... to encourage those values: L1 regularization adds an L1 penalty equal to the absolute value of the magnitude of coefficients....
Neptune.ai
neptune.ai › blog › fighting-overfitting-with-l1-or-l2-regularization
OpenAI to acquire Neptune | OpenAI
OpenAI is acquiring Neptune to deepen visibility into model behavior and strengthen the tools researchers use to track experiments and monitor training.
Medium
medium.com › analytics-vidhya › l1-vs-l2-regularization-which-is-better-d01068e6658c
L1 vs L2 Regularization: The intuitive difference | by Dhaval Taunk | Analytics Vidhya | Medium
January 22, 2024 - The main intuitive difference between the L1 and L2 regularization is that L1 regularization tries to estimate the median of the data while the L2 regularization tries to estimate the mean of the data to avoid overfitting. As we can see from the formula of L1 and L2 regularization, L1 regularization adds the penalty term in cost function by adding the absolute value of weight(Wj) parameters, while L2 regularization adds the squared value of weights(Wj) in the cost function.