The reason is the following. We use the notation:

Then

 [ this used:
[ this used:  the 1's in numerator cancel, then we used:
the 1's in numerator cancel, then we used:  ]
]
Since our original cost function is the form of:

Plugging in the two simplified expressions above, we obtain
 , which can be simplified to:
, which can be simplified to:

where the second equality follows from
 [ we used
[ we used  ]
]
All you need now is to compute the partial derivatives of  w.r.t.
w.r.t.  . As
$$\frac{\partial}{\partial \theta_j}y_i\theta x^i=y_ix^i_j, $$
$$\frac{\partial}{\partial \theta_j}\log(1+e^{\theta x^i})=\frac{x^i_je^{\theta x^i}}{1+e^{\theta x^i}}=x^i_jh_\theta(x^i),$$
. As
$$\frac{\partial}{\partial \theta_j}y_i\theta x^i=y_ix^i_j, $$
$$\frac{\partial}{\partial \theta_j}\log(1+e^{\theta x^i})=\frac{x^i_je^{\theta x^i}}{1+e^{\theta x^i}}=x^i_jh_\theta(x^i),$$
the thesis follows.
Answer from Avitus on Stack ExchangeThe reason is the following. We use the notation:
Then
[ this used: the 1's in numerator cancel, then we used: ]
Since our original cost function is the form of:
Plugging in the two simplified expressions above, we obtain
, which can be simplified to:
where the second equality follows from
[ we used ]
All you need now is to compute the partial derivatives of w.r.t. . As
$$\frac{\partial}{\partial \theta_j}y_i\theta x^i=y_ix^i_j, $$
$$\frac{\partial}{\partial \theta_j}\log(1+e^{\theta x^i})=\frac{x^i_je^{\theta x^i}}{1+e^{\theta x^i}}=x^i_jh_\theta(x^i),$$
the thesis follows.
You have to get the partial derivative with respect  . Remember that the hypothesis function here is equal to the sigmoid function which is a function of
. Remember that the hypothesis function here is equal to the sigmoid function which is a function of  ; in other words, we need to apply the chain rule. This is my approach:
; in other words, we need to apply the chain rule. This is my approach:


Anything without  is treated as constant:
is treated as constant:

Let's solve each derivative separately and then plug back in on (1):


Plug (3) and (2) in (1):


Notice that using the chain rule, the derivative of the hypothesis function can be understood as

where
 and
and

Plug (5) in (4):

Applying some algebra and solving subtraction:

There is a  factor missing on your expected answer.
factor missing on your expected answer.
Hope this helps.
How is the cost function from Logistic Regression differentiated - Cross Validated
How to get the derivatives of the logistic cost/loss function [TEACHING STAFF]
machine learning - Why the cost function of logistic regression has a logarithmic expression? - Stack Overflow
machine learning - Is it ok to define your own cost function for logistic regression? - Stack Overflow
Videos
Adapted from the notes in the course, which I don't see available (including this derivation) outside the notes contributed by students within the page of Andrew Ng's Coursera Machine Learning course.
In what follows, the superscript  denotes individual measurements or training "examples."
denotes individual measurements or training "examples."
$\small \frac{\partial J(\theta)}{\partial \theta_j} = \frac{\partial}{\partial \theta_j} \,\frac{-1}{m}\sum_{i=1}^m \left[ y^{(i)}\log\left(h_\theta \left(x^{(i)}\right)\right) + (1 -y^{(i)})\log\left(1-h_\theta \left(x^{(i)}\right)\right)\right] \\[2ex]\small\underset{\text{linearity}}= \,\frac{-1}{m}\,\sum_{i=1}^m \left[ y^{(i)}\frac{\partial}{\partial \theta_j}\log\left(h_\theta \left(x^{(i)}\right)\right) + (1 -y^{(i)})\frac{\partial}{\partial \theta_j}\log\left(1-h_\theta \left(x^{(i)}\right)\right) \right] \\[2ex]\Tiny\underset{\text{chain rule}}= \,\frac{-1}{m}\,\sum_{i=1}^m \left[ y^{(i)}\frac{\frac{\partial}{\partial \theta_j}h_\theta \left(x^{(i)}\right)}{h_\theta\left(x^{(i)}\right)} + (1 -y^{(i)})\frac{\frac{\partial}{\partial \theta_j}\left(1-h_\theta \left(x^{(i)}\right)\right)}{1-h_\theta\left(x^{(i)}\right)} \right] \\[2ex]\small\underset{h_\theta(x)=\sigma\left(\theta^\top x\right)}=\,\frac{-1}{m}\,\sum_{i=1}^m \left[ y^{(i)}\frac{\frac{\partial}{\partial \theta_j}\sigma\left(\theta^\top x^{(i)}\right)}{h_\theta\left(x^{(i)}\right)} + (1 -y^{(i)})\frac{\frac{\partial}{\partial \theta_j}\left(1-\sigma\left(\theta^\top x^{(i)}\right)\right)}{1-h_\theta\left(x^{(i)}\right)} \right] \\[2ex]\Tiny\underset{\sigma'}=\frac{-1}{m}\,\sum_{i=1}^m \left[ y^{(i)}\, \frac{\sigma\left(\theta^\top x^{(i)}\right)\left(1-\sigma\left(\theta^\top x^{(i)}\right)\right)\frac{\partial}{\partial \theta_j}\left(\theta^\top x^{(i)}\right)}{h_\theta\left(x^{(i)}\right)} - (1 -y^{(i)})\,\frac{\sigma\left(\theta^\top x^{(i)}\right)\left(1-\sigma\left(\theta^\top x^{(i)}\right)\right)\frac{\partial}{\partial \theta_j}\left(\theta^\top x^{(i)}\right)}{1-h_\theta\left(x^{(i)}\right)} \right] \\[2ex]\small\underset{\sigma\left(\theta^\top x\right)=h_\theta(x)}= \,\frac{-1}{m}\,\sum_{i=1}^m \left[ y^{(i)}\frac{h_\theta\left( x^{(i)}\right)\left(1-h_\theta\left( x^{(i)}\right)\right)\frac{\partial}{\partial \theta_j}\left(\theta^\top x^{(i)}\right)}{h_\theta\left(x^{(i)}\right)} - (1 -y^{(i)})\frac{h_\theta\left( x^{(i)}\right)\left(1-h_\theta\left(x^{(i)}\right)\right)\frac{\partial}{\partial \theta_j}\left( \theta^\top x^{(i)}\right)}{1-h_\theta\left(x^{(i)}\right)} \right] \\[2ex]\small\underset{\frac{\partial}{\partial \theta_j}\left(\theta^\top x^{(i)}\right)=x_j^{(i)}}=\,\frac{-1}{m}\,\sum_{i=1}^m \left[y^{(i)}\left(1-h_\theta\left(x^{(i)}\right)\right)x_j^{(i)}- \left(1-y^{i}\right)\,h_\theta\left(x^{(i)}\right)x_j^{(i)} \right] \\[2ex]\small\underset{\text{distribute}}=\,\frac{-1}{m}\,\sum_{i=1}^m \left[y^{i}-y^{i}h_\theta\left(x^{(i)}\right)- h_\theta\left(x^{(i)}\right)+y^{(i)}h_\theta\left(x^{(i)}\right) \right]\,x_j^{(i)} \\[2ex]\small\underset{\text{cancel}}=\,\frac{-1}{m}\,\sum_{i=1}^m \left[y^{(i)}-h_\theta\left(x^{(i)}\right)\right]\,x_j^{(i)} \\[2ex]\small=\frac{1}{m}\sum_{i=1}^m\left[h_\theta\left(x^{(i)}\right)-y^{(i)}\right]\,x_j^{(i)} $
The derivative of the sigmoid function is

To avoid impression of excessive complexity of the matter, let us just see the structure of solution.
With simplification and some abuse of notation, let  be a term in sum of
be a term in sum of  , and
, and  is a function of
is a function of  :
:

We may use chain rule:
 and solve it one by one (
and solve it one by one ( and
and  are constants).
are constants).
 For sigmoid
For sigmoid  holds,
which is just a denominator of the previous statement.
holds,
which is just a denominator of the previous statement.
Finally,  .
.
Combining results all together gives sought-for expression:
 Hope that helps.
Hope that helps.
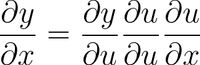
Source: my own notes taken during Standford's Machine Learning course in Coursera, by Andrew Ng. All credits to him and this organization. The course is freely available for anybody to be taken at their own pace. The images are made by myself using LaTeX (formulas) and R (graphics).
Hypothesis function
Logistic regression is used when the variable y that is wanted to be predicted can only take discrete values (i.e.: classification).
Considering a binary classification problem (y can only take two values), then having a set of parameters θ and set of input features x, the hypothesis function could be defined so that is bounded between [0, 1], in which g() represents the sigmoid function:

This hypothesis function represents at the same time the estimated probability that y = 1 on input x parameterized by θ:

Cost function
The cost function represents the optimization objective.

Although a possible definition of the cost function could be the mean of the Euclidean distance between the hypothesis h_θ(x) and the actual value y among all the m samples in the training set, as long as the hypothesis function is formed with the sigmoid function, this definition would result in a non-convex cost function, which means that a local minimum could be easily found before reaching the global minimum. In order to ensure the cost function is convex (and therefore ensure convergence to the global minimum), the cost function is transformed using the logarithm of the sigmoid function.

This way the optimization objective function can be defined as the mean of the costs/errors in the training set:

This cost function is simply a reformulation of the maximum-(log-)likelihood criterion.
The model of the logistic regression is:
P(y=1 | x) = logistic(θ x)
P(y=0 | x) = 1 - P(y=1 | x) = 1 - logistic(θ x)
The likelihood is written as:
L = P(y_0, ..., y_n | x_0, ..., x_n) = \prod_i P(y_i | x_i)
The log-likelihood is:
l = log L = \sum_i log P(y_i | x_i)
We want to find θ which maximizes the likelihood:
max_θ \prod_i P(y_i | x_i)
This is the same as maximizing the log-likelihood:
max_θ \sum_i log P(y_i | x_i)
We can rewrite this as a minimization of the cost C=-l:
min_θ \sum_i - log P(y_i | x_i)
P(y_i | x_i) = logistic(θ x_i) when y_i = 1
P(y_i | x_i) = 1 - logistic(θ x_i) when y_i = 0
Yes, you can define your own loss function, but if you're a novice, you're probably better off using one from the literature. There are conditions that loss functions should meet:
They should approximate the actual loss you're trying to minimize. As was said in the other answer, the standard loss functions for classification is zero-one-loss (misclassification rate) and the ones used for training classifiers are approximations of that loss.
The squared-error loss from linear regression isn't used because it doesn't approximate zero-one-loss well: when your model predicts +50 for some sample while the intended answer was +1 (positive class), the prediction is on the correct side of the decision boundary so the zero-one-loss is zero, but the squared-error loss is still 49² = 2401. Some training algorithms will waste a lot of time getting predictions very close to {-1, +1} instead of focusing on getting just the sign/class label right.(*)
The loss function should work with your intended optimization algorithm. That's why zero-one-loss is not used directly: it doesn't work with gradient-based optimization methods since it doesn't have a well-defined gradient (or even a subgradient, like the hinge loss for SVMs has).
The main algorithm that optimizes the zero-one-loss directly is the old perceptron algorithm.
Also, when you plug in a custom loss function, you're no longer building a logistic regression model but some other kind of linear classifier.
(*) Squared error is used with linear discriminant analysis, but that's usually solved in close form instead of iteratively.
The logistic function, hinge-loss, smoothed hinge-loss, etc. are used because they are upper bounds on the zero-one binary classification loss.
These functions generally also penalize examples that are correctly classified but are still near the decision boundary, thus creating a "margin."
So, if you are doing binary classification, then you should certainly choose a standard loss function.
If you are trying to solve a different problem, then a different loss function will likely perform better.