The UPDATE statement is given so that older fields can be updated to new value. If your older values are the same as your new ones, why would you need to update it in any case?
For eg. if your columns a to g are already set as 2 to 8; there would be no need to re-update it.
Alternatively, you can use:
INSERT INTO table (id,a,b,c,d,e,f,g)
VALUES (1,2,3,4,5,6,7,8)
ON DUPLICATE KEY
UPDATE a=a, b=b, c=c, d=d, e=e, f=f, g=g;
To get the id from LAST_INSERT_ID; you need to specify the backend app you're using for the same.
For LuaSQL, a conn:getlastautoid() fetches the value.
The UPDATE statement is given so that older fields can be updated to new value. If your older values are the same as your new ones, why would you need to update it in any case?
For eg. if your columns a to g are already set as 2 to 8; there would be no need to re-update it.
Alternatively, you can use:
INSERT INTO table (id,a,b,c,d,e,f,g)
VALUES (1,2,3,4,5,6,7,8)
ON DUPLICATE KEY
UPDATE a=a, b=b, c=c, d=d, e=e, f=f, g=g;
To get the id from LAST_INSERT_ID; you need to specify the backend app you're using for the same.
For LuaSQL, a conn:getlastautoid() fetches the value.
There is a MySQL specific extension to SQL that may be what you want - REPLACE INTO
However it does not work quite the same as 'ON DUPLICATE UPDATE'
It deletes the old row that clashes with the new row and then inserts the new row. So long as you don't have a primary key on the table that would be fine, but if you do, then if any other table references that primary key
You can't reference the values in the old rows so you can't do an equivalent of
INSERT INTO mytable (id, a, b, c) values ( 1, 2, 3, 4) ON DUPLICATE KEY UPDATE id=1, a=2, b=3, c=c + 1;
I'd like to use the work around to get the ID to!
That should work — last_insert_id() should have the correct value so long as your primary key is auto-incrementing.
However as I said, if you actually use that primary key in other tables, REPLACE INTO probably won't be acceptable to you, as it deletes the old row that clashed via the unique key.
Someone else suggested before you can reduce some typing by doing:
INSERT INTO `tableName` (`a`,`b`,`c`) VALUES (1,2,3)
ON DUPLICATE KEY UPDATE `a`=VALUES(`a`), `b`=VALUES(`b`), `c`=VALUES(`c`);
Videos
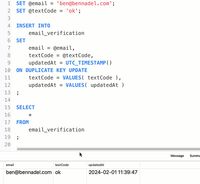
The fastest operation will be the one that has the most chances of succeeding immediately. You should find out what happens more often: inserting new rows or updating old ones. Code accordingly.
So I decided to TEST both methods in my application and using the actual database. In the performed test, I'll refer to "METHOD 1" as the one in which we check for affected rows and insert if necessary, and subsequently refer to "METHOD 2" as using INSERT INTO.. ON DUPLICATE KEY UPDATE. Both methods have been ran on actual data 20 times with at least 5 seconds gap between tests:

So as to answer my own doubt, at least in case of UPDATES, using the 1st method is the winner, though the 2nd one isn't bad either.
Unfortunately not.
You can get half-way there by not having to repeat the value:
INSERT INTO `tableName` (`a`,`b`,`c`) VALUES (1,2,3)
ON DUPLICATE KEY UPDATE `a`=VALUES(`a`), `b`=VALUES(`b`), `c`=VALUES(`c`);
But you still have to list the columns.
use REPLACE INTO
The meaning of REPLACE INTO is that IF the new record presents new key values, then it will be inserted as anew record.
IF the new record has key values that match a pre-existing record,then the key violation will be ignored and the new record will replace the pre-existing record.
Beginning with MySQL 8.0.19 you can use an alias for that row (see reference).
INSERT INTO beautiful (name, age)
VALUES
('Helen', 24),
('Katrina', 21),
('Samia', 22),
('Hui Ling', 25),
('Yumie', 29)
AS new
ON DUPLICATE KEY UPDATE
age = new.age
...
For earlier versions use the keyword VALUES (see reference, deprecated with MySQL 8.0.20).
INSERT INTO beautiful (name, age)
VALUES
('Helen', 24),
('Katrina', 21),
('Samia', 22),
('Hui Ling', 25),
('Yumie', 29)
ON DUPLICATE KEY UPDATE
age = VALUES(age),
...
I was looking for the same behavior using jdbi's BindBeanList and found the syntax is exactly the same as Peter Lang's answer above. In case anybody is running into this question, here's my code:
@SqlUpdate("INSERT INTO table_one (col_one, col_two) VALUES <beans> ON DUPLICATE KEY UPDATE col_one=VALUES(col_one), col_two=VALUES(col_two)")
void insertBeans(@BindBeanList(value = "beans", propertyNames = {"colOne", "colTwo"}) List<Beans> beans);
One key detail to note is that the propertyName you specify within @BindBeanList annotation is not same as the column name you pass into the VALUES() call on update.
I suggest you to use IF() to do that.
Refer: conditional-duplicate-key-updates-with-mysql
INSERT INTO daily_events (created_on, last_event_id, last_event_created_at)
VALUES ('2010-01-19', 23, '2010-01-19 10:23:11')
ON DUPLICATE KEY UPDATE
last_event_id = IF(last_event_created_at < VALUES(last_event_created_at), VALUES(last_event_id), last_event_id);
This is our final solution, works like a charm!
The insert ignore will make sure that the row exists on both the master and slave, in case they've ever diverted.
The update ... where makes sure that only the most recent update, globally, is the end result after all replication is done.
mysql> desc test;
+-------+--------------+------+-----+-------------------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+-------------------+-------+
| id | int(11) | NO | PRI | NULL | |
| value | varchar(255) | YES | | NULL | |
| ts | timestamp | NO | | CURRENT_TIMESTAMP | |
+-------+--------------+------+-----+-------------------+-------+
mysql> insert ignore into test values (4, "foo", now());
mysql> update test set value = "foo", ts = now() where id = 4 and ts <= now();