"..approach classification problem through regression.." by "regression" I will assume you mean linear regression, and I will compare this approach to the "classification" approach of fitting a logistic regression model.
Before we do this, it is important to clarify the distinction between regression and classification models. Regression models predict a continuous variable, such as rainfall amount or sunlight intensity. They can also predict probabilities, such as the probability that an image contains a cat. A probability-predicting regression model can be used as part of a classifier by imposing a decision rule - for example, if the probability is 50% or more, decide it's a cat.
Logistic regression predicts probabilities, and is therefore a regression algorithm. However, it is commonly described as a classification method in the machine learning literature, because it can be (and is often) used to make classifiers. There are also "true" classification algorithms, such as SVM, which only predict an outcome and do not provide a probability. We won't discuss this kind of algorithm here.
Linear vs. Logistic Regression on Classification Problems
As Andrew Ng explains it, with linear regression you fit a polynomial through the data - say, like on the example below we're fitting a straight line through {tumor size, tumor type} sample set:
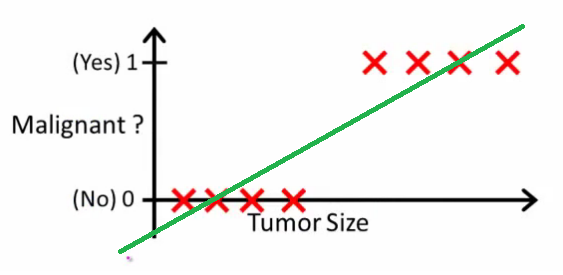
Above, malignant tumors get  and non-malignant ones get
and non-malignant ones get  , and the green line is our hypothesis
, and the green line is our hypothesis  . To make predictions we may say that for any given tumor size
. To make predictions we may say that for any given tumor size  , if
, if  gets bigger than
gets bigger than  we predict malignant tumor, otherwise we predict benign.
we predict malignant tumor, otherwise we predict benign.
Looks like this way we could correctly predict every single training set sample, but now let's change the task a bit.
Intuitively it's clear that all tumors larger certain threshold are malignant. So let's add another sample with a huge tumor size, and run linear regression again:
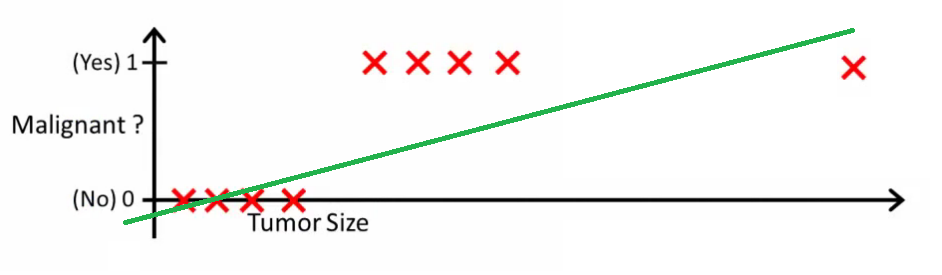
Now our $h(x) > 0.5 \rightarrow malignant$ doesn't work anymore. To keep making correct predictions we need to change it to  or something - but that not how the algorithm should work.
or something - but that not how the algorithm should work.
We cannot change the hypothesis each time a new sample arrives. Instead, we should learn it off the training set data, and then (using the hypothesis we've learned) make correct predictions for the data we haven't seen before.
Hope this explains why linear regression is not the best fit for classification problems! Also, you might want to watch VI. Logistic Regression. Classification video on ml-class.org which explains the idea in more detail.
EDIT
probabilityislogic asked what a good classifier would do. In this particular example you would probably use logistic regression which might learn a hypothesis like this (I'm just making this up):
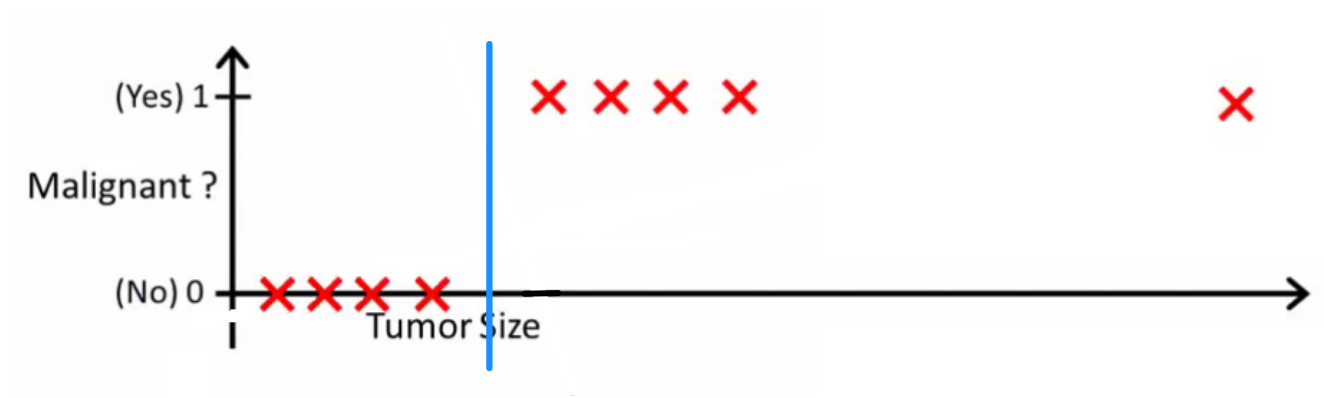
Note that both linear regression and logistic regression give you a straight line (or a higher order polynomial) but those lines have different meaning:
 for linear regression interpolates, or extrapolates, the output and predicts the value for
for linear regression interpolates, or extrapolates, the output and predicts the value for  we haven't seen. It's simply like plugging a new
we haven't seen. It's simply like plugging a new  and getting a raw number, and is more suitable for tasks like predicting, say car price based on {car size, car age} etc.
and getting a raw number, and is more suitable for tasks like predicting, say car price based on {car size, car age} etc. for logistic regression tells you the probability that
for logistic regression tells you the probability that  belongs to the "positive" class. This is why it is called a regression algorithm - it estimates a continuous quantity, the probability. However, if you set a threshold on the probability, such as
belongs to the "positive" class. This is why it is called a regression algorithm - it estimates a continuous quantity, the probability. However, if you set a threshold on the probability, such as  , you obtain a classifier, and in many cases this is what is done with the output from a logistic regression model. This is equivalent to putting a line on the plot: all points sitting above the classifier line belong to one class while the points below belong to the other class.
, you obtain a classifier, and in many cases this is what is done with the output from a logistic regression model. This is equivalent to putting a line on the plot: all points sitting above the classifier line belong to one class while the points below belong to the other class.
So, the bottom line is that in classification scenario we use a completely different reasoning and a completely different algorithm than in regression scenario.
Answer from andreister on Stack ExchangeRegression to Solve Classification problem: Good or Rubbish?
Why doesn’t linear regression work on classification problems?
Videos
"..approach classification problem through regression.." by "regression" I will assume you mean linear regression, and I will compare this approach to the "classification" approach of fitting a logistic regression model.
Before we do this, it is important to clarify the distinction between regression and classification models. Regression models predict a continuous variable, such as rainfall amount or sunlight intensity. They can also predict probabilities, such as the probability that an image contains a cat. A probability-predicting regression model can be used as part of a classifier by imposing a decision rule - for example, if the probability is 50% or more, decide it's a cat.
Logistic regression predicts probabilities, and is therefore a regression algorithm. However, it is commonly described as a classification method in the machine learning literature, because it can be (and is often) used to make classifiers. There are also "true" classification algorithms, such as SVM, which only predict an outcome and do not provide a probability. We won't discuss this kind of algorithm here.
Linear vs. Logistic Regression on Classification Problems
As Andrew Ng explains it, with linear regression you fit a polynomial through the data - say, like on the example below we're fitting a straight line through {tumor size, tumor type} sample set:
Above, malignant tumors get and non-malignant ones get , and the green line is our hypothesis . To make predictions we may say that for any given tumor size , if gets bigger than we predict malignant tumor, otherwise we predict benign.
Looks like this way we could correctly predict every single training set sample, but now let's change the task a bit.
Intuitively it's clear that all tumors larger certain threshold are malignant. So let's add another sample with a huge tumor size, and run linear regression again:
Now our $h(x) > 0.5 \rightarrow malignant$ doesn't work anymore. To keep making correct predictions we need to change it to or something - but that not how the algorithm should work.
We cannot change the hypothesis each time a new sample arrives. Instead, we should learn it off the training set data, and then (using the hypothesis we've learned) make correct predictions for the data we haven't seen before.
Hope this explains why linear regression is not the best fit for classification problems! Also, you might want to watch VI. Logistic Regression. Classification video on ml-class.org which explains the idea in more detail.
EDIT
probabilityislogic asked what a good classifier would do. In this particular example you would probably use logistic regression which might learn a hypothesis like this (I'm just making this up):
Note that both linear regression and logistic regression give you a straight line (or a higher order polynomial) but those lines have different meaning:
- for linear regression interpolates, or extrapolates, the output and predicts the value for we haven't seen. It's simply like plugging a new and getting a raw number, and is more suitable for tasks like predicting, say car price based on {car size, car age} etc.
- for logistic regression tells you the probability that belongs to the "positive" class. This is why it is called a regression algorithm - it estimates a continuous quantity, the probability. However, if you set a threshold on the probability, such as , you obtain a classifier, and in many cases this is what is done with the output from a logistic regression model. This is equivalent to putting a line on the plot: all points sitting above the classifier line belong to one class while the points below belong to the other class.
So, the bottom line is that in classification scenario we use a completely different reasoning and a completely different algorithm than in regression scenario.
I can't think of an example in which classification is actually the ultimate goal. Almost always the real goal is to make accurate predictions, e.g., of probabilities. In that spirit, (logistic) regression is your friend.
Hello DSs!
Thought I’d share this here and listen to different opinions. So I have/had a classification problem and of course I had tried most of the classification algorithms (from Random forest to AdaBoot, etc). I wanted to try XGBoost when I had the idea to treat it as a regression problem. So I fit the dataset with the binary classes using the XGB regressor. I then predicted the test set on it. Of course l, the output was continuous (i.e. 0.11, 0.2 etc). Of course, this can’t be passed into the classification evaluation metrics.
I then set a normal benchmark (<0.5:0, >=0.5:1). After running the evaluation metrics on the new result, I was surprised to see an accuracy of 0.83 and even high precision and recall for the unrepresented class. Has anyone else tried this? Do you guys think it’s rubbish?
Hello. Im a beginner in ML. I’m trying to really understand why linear regression doesn’t work on classification problems.
I often the answers along the lines of: “it predicts continuous values” or “finds the best fit lines” or something similar.
This is quite difficult for me to intuitively grasp and I’ve been stuck trying to figure this out for more than 3 weeks now.
I’m working on a titanic dataset and trying to use linear regression but I do not even know how to make it work with linear regression.
I understand that’s not what LR is meant for but I just I want to really see and understand why that’s so.
If possible explain like a total newb. No complex or tacit language