Videos
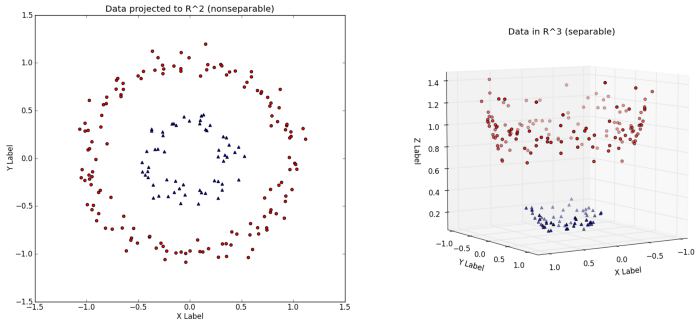
In principle, a Kernel is just a feature transformation in an (infinite) feature space. It is often the case, that your feature space is to simple/small, so that you are not able to divide the data properly (in a linear way). Just look at the pciture of this blog (https://towardsdatascience.com/understanding-the-kernel-trick-e0bc6112ef78): In an 2D Feature space, you have no chance to separte datapoints in a linear way. Therefore just use a transformation (gaussian-kernel, polynomial kernel, etc. ) to achieve a higher feature space. In the 3D space, the circle can be divided by a linear function.
In principal, those kernels are just a function, which is computed on every datapoint. The mathematical trick behind those kernels is, that you do not have to actually compute this transformation on each datapoint. But this goes to far i think.
We define kernels as real-valued functions $\kappa(x,x')\in\mathbb{R}$ where $x,x'\in\mathbb{R}^n$.
Typically,
- $\kappa(x,x')\geq 0$
- $\kappa(x,x')=\kappa(x',x)$
So a kernel can be interpreted as a measure of similarity. For example, $$\kappa(x,x')=x^Tx'$$
What we use in support vector machines are Mercer kernels. If a kernel is Mercer, then there exists a function $\phi:\mathbb{R}^n\rightarrow\mathbb{R}^m$ for some $m$ (which can also be infinite as in the case of the RBF kernel), such that:
$$\kappa(x,x')=\phi(x)^T\phi(x')$$
For example, let $\kappa(x,x') = (1+x^Tx')^2$ for $x,x'\in\mathbb{R}^2$.
$\Rightarrow\kappa(x,x') = (1+x_1x'_1+x_2x'_2)^2$
$\Rightarrow\kappa(x,x') = 1+2x_1x'_1+2x_2x'_2+(x_1x'_1)^2+(x_2x'_2)^2+2x_1x'_1x_2x'_2$
$\kappa(x,x')$ can be written as $\phi(x)^T\phi(x')$ where $\phi(x) = [1,\sqrt{2}x_1,\sqrt{2}x_2,x_1^2,x_2^2,\sqrt{2}x_1x_2]^T$.
So this kernel is equivalent to working in a 6-dimensional space.
Also, the complexity to get $(1+x^Tx')^2$ for $x,x'\in\mathbb{R}^2$ is lesser than the complexity to get $\phi(x)^T\phi(x')$ for $\phi(x),\phi(x')\in\mathbb{R}^6$.